
The Great Red Bead Experiment Simulator
An Educational Toy for Testing Dr. Deming's Assertion About Rational Predictions and Random Numbers


THE AIM for this subscriber-exclusive post is to provide you with early access to an updated simulation I developed a couple of years ago to test Dr. Deming’s hypothesis about a rational basis for predicting the outcomes of successive runs of his famous Red Bead Experiment, which I first wrote about in my Feb 3/22 newsletter.
In Out of the Crisis, Deming describes how after running the experiment he would ask students what they thought the cumulative average of red beads would be if they were to carry out successive runs into the future. Recall that the standard experiment has six “willing workers” drawing samples of 50 beads from a bucket containing an 80/20 mix of 3,200 white beads to 800 red beads:
Cumulated average. Question : As 20 per cent of the beads in the box are red, what do you think would be the cumulated average, the statistical limit, as we continue to produce lots by the same process over many days?
The answer that comes forth spontaneously from the audience is that it must be 10 because 10 is 20 per cent of 50, the size of a lot. Wrong.
We have no basis for such a statement. As a matter of fact, the cumulated average for paddle No. 2 over many experiments in the past has settled down to 9.4 red beads per lot of 50. Paddle No. 1, used for 30 years, shows an average of 11.3.
The paddle is an important piece of information about the process. Would the reader have thought so prior to these figures?
Deming, W. Edwards. Out of the Crisis (MIT Press) 2nd Ed (pp. 351-352), 3rd Ed (pp. 300-301). The MIT Press. Kindle Edition.
Dr. Deming then proposes a method to prove his assertion based on his sound understanding of variation in a system and statistical sampling theory (which he wrote an entire book about):
Sampling by use of random numbers. If we were to form lots by use of random numbers, then the cumulated average, the statistical limit of x-BAR, would be 10. The reason is that the random numbers pay no attention to color, nor to size, nor to any other physical characteristic of beads, paddle, or employee. Statistical theory (theory of probability) as taught in the books for the theory of sampling and theory of distributions applies in the use of random numbers, but not in experiences of life. Once statistical control is established, then a distribution exists, and is predictable.
Deming, W. Edwards. Out of the Crisis (MIT Press) 2nd Ed (p. 353), 3rd Ed (p. 301). The MIT Press. Kindle Edition.
To my knowledge, Dr. Deming never got around to actually trying this out, which would have been onerous for him, especially when he knew his statistical theory inside and out. However, my curiosity was piqued and I needed to find out for myself: so I created RedBeadSim in Python test if his assertion about rational predictions and random numbers was true.
What You Need to Play with RedBeadSim
For the impatient who understand the rudiments of running Python code on their own machine, you can download a copy of the simulation from my GitHub page, where you will also find the documentation:
Running the Simulation
Assuming that you have already installed Python and the required libraries (numpy and plotly), you can run the sim from the command line using:
python RedBeadSim.py
This will generate a “stock” simulation of 10 Red Bead Experiments yielding 240 data points (6 willing workers * 4 days * 10 runs) in a standard Process Behaviour Chart, which will look something like the following:

Zooming in to the header, we can see what parameters were used to generate the simulation along with the calculated mean, upper process limit, and lower process limit, and how many data points were used to calculate them in the Baseline Sample Count:

Note that in this run, Dr. Deming’s view on the cumulative average settling to “10” is vindicated, however, I have found over many, many iterations this can vary from 9.6 to 11 (!!) depending on the method used to draw the samples in the code. In the stock simulation, I use Python’s built-in Random.Sample() method to draw a paddle of beads, however you can also use my own custom sampling method with the following syntax:
python RedBeadSim.py —-customSampleMethod
This produces a cumulative average much closer to 10 for reasons I can’t fully explain, yet, but I am guessing has to do with how Python handles random numbers. More investigation is required!
Changing the Baseline Sample Period
In the stock run the mean and process limits for both the X and mR charts are calculated against the entire data set. As I explain in my Sept. 18/23 newsletter, Dr. Wheeler teaches us that we can get the best predictive power from the first 30-35 data points of any data set, with the utility tapering off as the limits harden around 40-50, so 240 is extreme overkill. Suppose we want to test calculating limits using the results of the first two experiments? This would be 2 experiments * 24 samples = 48 data points, which you can simulate with:
python RedBeadSim.py —-baselineSamplePeriod 48
This will generate a PBC like the one below, with the data points conveniently highlighted and labeled:

Changing the Paddle Size
In my debriefs of the Red Bead Experiment, I ask participants how we could reduce the number of red beads drawn in each sample. This usually leads into a discussion about why the red beads are in the bucket in the first place and working upstream to find the causes. However, there’s another more pragmatic way: cover up part of the paddle with tape, effectively reducing the lot size.
You can simulate this by specifying the number of divots in your virtual paddle to say, 25, using:
python RedBeadSim.py —-paddleLotSize 25
As you might expect, this halves the cumulative average, but you can still draw a surprising number of red beads:

Changing the Number of Experiments to Run
Suppose you want to simulate 100 Red Bead Experiments in a row? Try:
python RedBeadSim.py —-experimentCycles 100
Be prepared for a slight delay while your machine goes ‘brrr’ and produces a very crowded PBC like this:

Using Plotly’s Built-In Features
Plotly is an amazing open source graphing and charting library for Python that renders slick, interactive charts in your browser. You may have already noticed that as you hover your pointer over the data points it shows a tooltip with the current data point index and value:
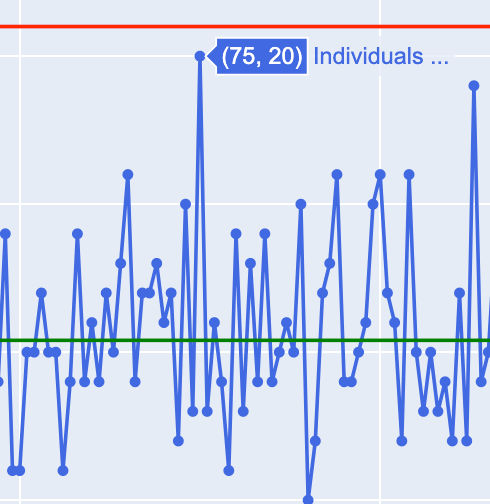
You can also “zoom in” to a segment of the data by clicking and dragging a selection box, save a plot as a .png, and “pan” around larger data sets that you’re analyzing.
Upcoming Features
What’s next for RedBeadSim? I have some ideas for new features that occurred to me while getting this release ready:
Exporting simulation data to an Excel worksheet
Rendering the simulation data as a histogram to show frequencies
Highlighting weak signals like eight or more data points above or below the mean, which I’ve observed happening in some runs
Related Posts
For those who have either forgotten or aren’t aware, I’ve written about the Red Bead Experiment and Process Behaviour Charts in several newsletters that you might find interesting and useful to interpret this simulation:
Thoughts, Comments, Suggestions…
Paid-tier subscribers like you (yes, YOU!) will have early access to RedBeadSim for the next week while I am on a brief vacation, after which I will announce it for general availability to all subs. In the interim, give it a try and let me know your thoughts and impressions in the comments below, or by sending me a direct message via Substack.
Cheers,
