
Red Bead Redux
Reviewing My Run of Deming's Famous Experiment for AgileTO


THE AIM for today’s entry is to recap my recent facilitation of Dr. Deming’s Red Bead Experiment with my colleague Jeff Kosciejew for the AgileTO meetup in downtown Toronto last night.
My objective last night was to deliver a refreshed update of the Experiment with some industry-specific tweaks and to lean in on the theme of a rational basis for prediction, building on an earlier session Jeff delivered on probabilistic forecasting for agile software delivery.
UPDATE (5/12/23): Download my session slides and Excel spreadsheet here.

What Changed?
I’ve run the experiment many times using Steve Prevette’s rendition as a model featuring six Willing Workers, two QA, an "Inspector-General” with a loud, booming voice, and a Recorder for results. Over time I’ve developed an Excel spreadsheet that makes capturing the data and analyzing it in-situ faster and a bit more mistake-proof.
As this would be my first time running the experiment since 2018 (!) I decided to add some twists that would resonate with my target audience and keep up with the times:
Instead of having Above-Average Willing Workers, I had Willing 10x Developers, a riff on a much-maligned, but equivalent meme in software delivery.
Instead of having an Inspector General, I had a Product Owner - a role in a Scrum Team who’s responsible for the delivery of a product and working closely with the developers to get increments of functionality out into production.
Instead of a Recorder, I had a Data Analyst who would record results reported from the PO on a card and aid me in getting the results into our Scorecard(tm) system, an Excel spreadsheet that the nephew of the VP of IT had designed for us. (“The best $200 we ever spent.”)
The paddle was now a 5x10 array that was being passed to a RESTful API returning data they needed to “scrub” for errors. QA would record and inspect the results independently, then the PO would report the defect counts for each 10x Developer to the Data Analyst. Red beads were synonymous to “Escaped Defects”.
Instead of running the experiment over four days, I changed it to four “Sprints” - a reference to the standard work schedule unit in the Scrum software delivery framework that usually lasts 1-2 weeks.
In the past, Scrum teams would estimate their work using a fungible metric called “Story Points” that was meant to convey a rough approximation of effort and time. I played on this by establishing we had “1200 Points” of work to deliver to our customer (50 beads/paddle * 6 Developers * 4 Days = 1,200 white beads). I also incorporated another throwback to old-school Scrum project management with a “Sprint Burndown” chart in the Scorecard system to show remaining effort after each Sprint:

To keep the audience engaged, I provided copies of the Scorecards used by QA and Data Analysis, allowing everyone to follow along and verify the accuracy of our on-the-fly calculations:

Instead of setting an arbitrary goal of 3 Escaped Defects (Red Beads) or less, I hammed-up that top-management had just read an article by Jeff Gothelf about OKRs and that henceforth all teams would have an OKR of 3 Escaped Defects per developer per Sprint. As usual, we baited the hook with a crisp Canadian $20 bill after Sprint 2.
Before Sprint 2 I announced that we had a Lean Process Efficiency consultant advise us that we could optimize our operations by implementing single piece flow and to reduce the waste of motion (as CEO Kosciejew observed), so we lined up our Developers along a table and had them sift beads and present to QA in one go, passing the bucket and paddle down the line before returning it to the starting position.
Yes, Someone Got the OKR Bonus…
For the second time in all my runs of this experiment, we had a Developer win the $20 OKR on-the-spot award at the start of Sprint 3! More than happy to pay this out as it is an extraordinarily rare for this to happen.

Yes, Someone Got Fired…
A good friend and colleague who played the role of 10x Developer #6 managed to pull the worst result on Sprint 1 (18 escaped defects!) earning himself a Performance Improvement Plan. During Sprint 2 he began manipulating beads with his fingers to improve his results. Such insubordination could not be tolerated and I reluctantly fired him on the spot. Sincere apologies, Mitchell - you took your termination well.
Their Replacement Protested Being Stack-Ranked
During the Sprint 3 performance appraisals, Developer #6’s replacement protested that they were being unfairly evaluated on the results of their predecessor. I protested that the computer can’t be wrong, and asked whether they thought some other star performer should go under the bus for them. In the end, Developer #2 made the ultimate sacrifice for their teammate (thank you, Ana!) and took early retirement, and was packaged-out.
The Results Are In…
Here’s a snapshot of our results after we entered them into our $200 performance management system. As shown we delivered 966/1200 points or “White Beads” of work, or about 80%.

Some clarifying notes:
The asterisk beside Developer 5 denotes they were our star performer for Sprint 1, earning a coveted Sprint One Award from CEO Kosciejew. Unfortunately, they would later be laid off at the end of Sprint 3 due to poor performance. Developer 6 was put on a Performance Improvement Plan for their efforts.
The cells under “Perf.” denote who is above-average (fewest red beads) and below-average (most red beads) for the purposes of stack-ranking and termination. The top-3 moved on to Sprint 4 with double shifts.
The “Burndown” figures represent how many white beads remained to deliver based on the Sprint’s tally, working down from the initial total of 1,200.
The “Escaped Defects” are representation of the % of the red beads to white beads for the Sprint’s tally, eg. in the first column, 66/234=28%.
The “Cumulative AVG” is the average of the red beads delivered for the Sprint.
The Team Delivered, But Not Well Enough
As by design, the conclusions of the experiment are always a given: Our customer cancels the contract, we end up in regulatory compliance quagmires and have to declare bankruptcy and close the business for shareholder and creditor protection. Nevertheless, our intrepid band of 10x Developers managed to reduce their Escaped Defects (red beads) after Sprint 2 to an impressive 16%!

Visualizing the System and Management Interventions
In the debrief, we examined the entrails of our system with a live-constructed Process Behaviour Chart. I’ve included visual annotations to show all the management interventions that were made and how they had zero effect on the performance of the system: It carried on, regardless. It showed that our operation was stable and predictable and operating perfectly, as designed.

Q: Predict Cumulative Average Red Beads?
As I mention above, my aim was to direct this run of the Experiment toward the theme of prediction, so I took a page from Dr. Deming and asked the participants to predict the cumulative average of the system into the future, given:
A mixture of 4,000 white and red beads in an 80/20 distribution, and;
A paddle with 50 indentations
We referred back to our Scorecard to see each Sprint’s average and overall average over four Sprints to give us a baseline.

As expected, the answer of “10” came up after doing some simple math: 20% of 50 = 10. I challenged this by asking what the basis of that prediction was and whether the interactions of the system components were considered, which have inherent variation, ie. Developer + Paddle + Beads. It could only be 10 if each bead stood an equal probability of being selected as any the other, irrespective of colour. I reinforced this by live-demoing a Python app that simulated 240 samplings using random numbers, creating a visualization of a perfectly stable system with a mean of 10:

Each bead in the kit has imperfections, including the paddle, causing unknown and unknowable interactions with each other, yielding unique patterns of variation inherent to the system. As Deming himself observed over hundreds of iterations he facilitated, different paddles can produce markedly different cumulative averages.

The Punch-Line: Don’t Forecast an Unstable System
The proposal I wanted to put before the AgileTO community was simple: Don’t forecast a system using statistics like Confidence Intervals if you do not know whether it is stable and predictable, ie. presenting no special causes of variation above the process limits. I then live demoed a site that uses Enumerative Study statistics (ie. those that are used for sampling) to aggregate and visualize software development data for the purposes of analysis and forecasting. The top histogram shows a distribution of work items completed in a day with a rudimentary Confidence Interval of 85% falling into 4 or fewer for the first 30d as shown on the lower run chart.

I then moved the 30d window along the run chart and demonstrated how the distribution continually shifts, according to the 30d being sampled. I did this to reinforce the point that for systems, empirical evidence is never complete and we need a different view if we’re to understand whether we could forecast this system’s throughput performance into the future.
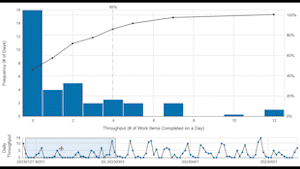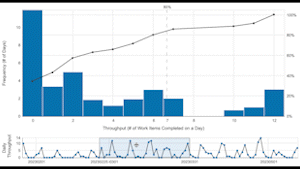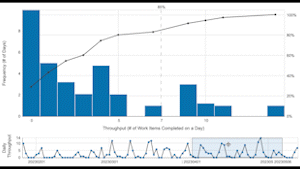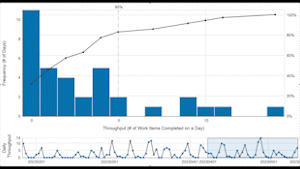
So, we looked at the data through the lens of a PBC, which showed multiple signals above the upper process limit:

Lesson #1: This system is presenting multiple signals of special causes (each highlighted datapoint above the red line), indicating it is neither stable nor predictable. Each signal needs to be investigated to understand what’s behind the jumps in throughput before a forecast can even be attempted. The team and management then need to work on bringing the system into a stable and predictable state to enable more reliable forecasts. The aim is to deliver at a pace the customer can absorb/use and the team can sustain without having to make heroic “pushes” to get everything done.
NB: The signals we see here could also be attributable to bug fixes, which we could confirm by looking at the backlog. If so, the next logical question would be what’s causing them?
Lesson #2: Consistent with the advice my colleague Jeff provided at a prior session, this chart demonstrates why you don’t want to forecast off the average (green line): customers (and teams!) don’t feel averages as much as they feel the extremes, which is the variation around the mean.
Concluding Lessons:
I rounded out our session with some concluding “Management Cheat Codes” to jump-start participants’ thinking about connecting the lessons of the experiment to their real-world experiences:
Management in any form is prediction. This means having a theory to interpret experience, evidence, and data.
The majority of performance and problems belong to the system, not people.
Don’t use sampling statistics to forecast the performance of a system without understanding whether it is stable and predictable. Keep in mind that empirical evidence is never complete.
Knowledge has temporal spread: Visualize system data on a PBC for evidence of stability/predictability before making forecasts.
Conclusion: Good Time Had by All
There was a lot of keen interest demonstrated by the participants and audience who turned out for the event. Some shared personal stories that reinforced the lessons of the red beads, while others gave sharp insights into the mechanics of the experiment itself. I was bombarded with questions which I hope I answered well enough, and there were certainly more left unanswered due to time.
A BIG thank-you goes out to my old partner in crime and colleague, Jeff Kosciejew, who reprised his role as CEO and played the role extremely well, offering just the right interventions at just the right times, and for getting us cool custom-made, branded hoodies proudly displaying the White Bead Corp. logo.

Profound writings Cristhopher! Demings thinking is (probably) most focused on variation in systems. He also gave us an understanding of what a system is and why learning and phsycholgy are important elements for developing better ways of thinking and improvement. Thank you for supporting Deming!